Data Modelling
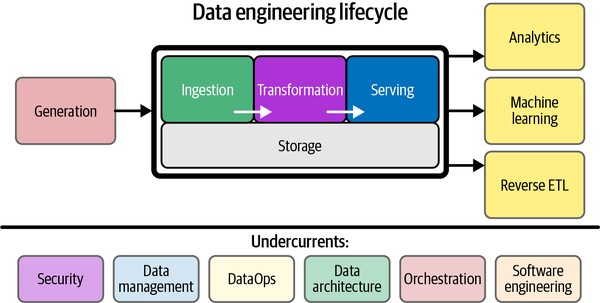
Source: https://medium.com/@dom.n/the-data-engineering-lifecycle-5c67bf6fb540
What is Data Engineering?
Data Engineering is the process of designing and defining pipelines that collect raw data from different sources and make the data compatible for analysis – deriving business value.
To be a successful Data Engineer, one needs to understand certain data concepts, and I would like to explain some of those in detail in this 10 part series. The first concept that we will discuss is Data Modeling.
What is Data Modeling?
Data modeling is the process of conceptualizing and visualizing how data will be captured, stored, and used by an organization. The ultimate aim of data modeling is to establish clear data standards for your entire organization.
There are 3 main types of Data Models:
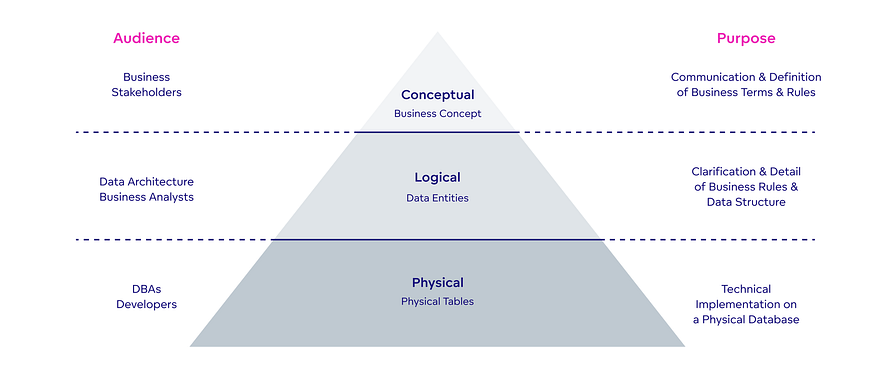
a. Conceptual Data Model:*
These models are designed in an effort to communicate with stakeholders showing relationships between different entities and defining their essential attributes according to the business requirements. It is an abstract version represented by ER or UML diagrams to confirm with the goal and scope of the data project.*
b. Logical Data Model:These models are refined versions of conceptual data models and incorporate the details of cardinality, data types, contraints, validation as proposed by business rules. It can also be defined using ER or UML diagrams.
c. Physical Data Model:These models are the final version of the logical data model which inlcudes all the technical features and limitations of the storage option you decide upon and is specifically optimized for performance, scalability, security and availability of your data.
Zoom image will be displayed
Source: https://www.gooddata.com/blog/what-a-data-model/
Data modeling techniques
There are several data modeling techniques that we could use to store the data in a database:
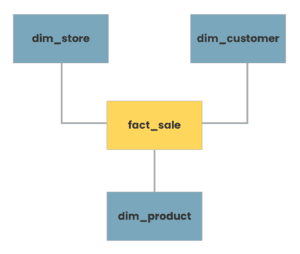
Dimensional data modeling: This type of data modeling is used for data analytics in data warehouses and organizing your data into facts(numerical measures of business events- sales,profit) and dimensions(descriptive attributes that provide context about the fact-order, customer).
Source: https://www.phdata.io/blog/building-modern-data-platform-with-data-vault/
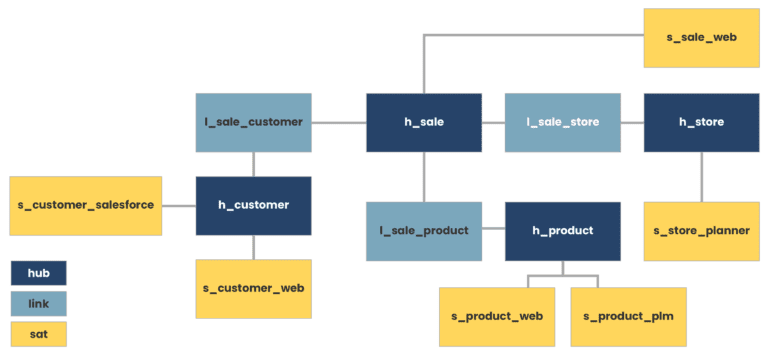
Data vault data modeling: A data vault is a type of data model that enables quick integration of new data sources into existing models. It is an insert only architecture and allows historical record tracking. It consists of 3 components — a hub(a core business entity and unique keys defining it), a link(a relationship between business keys of two or more hubs) and a satellite(houses all contextual data about an entity).
Zoom image will be displayed
Source: https://www.phdata.io/blog/building-modern-data-platform-with-data-vault/
Graph data modeling: Graph data model is a model made for graph databases that represent data that is the form of networks like social media interactions. It consists of nodes(entities), properties(attributes) and relationships as edges. We can leverage the graph algorithms and graph queries to perform analysis on this type of model.
Zoom image will be displayed
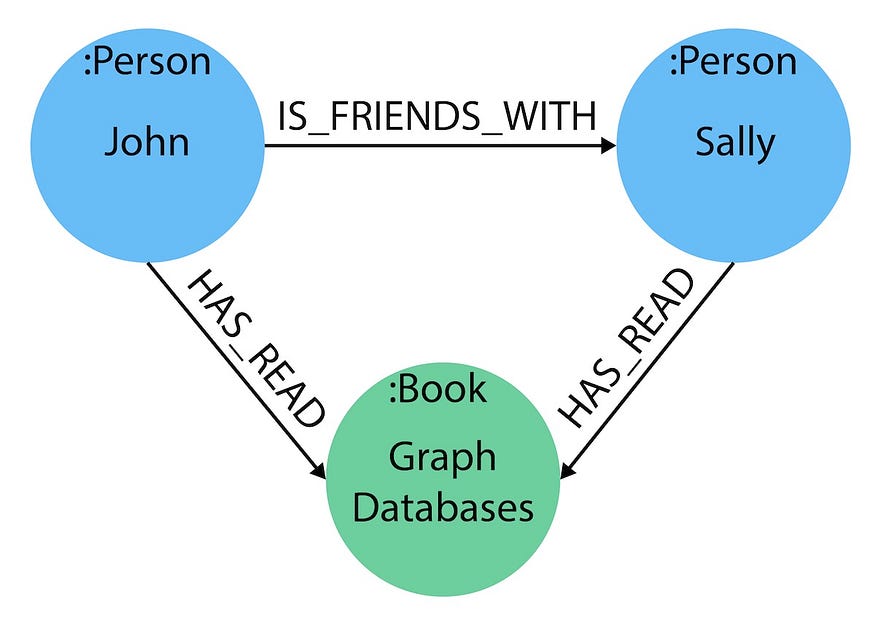
Source: https://neo4j.com/developer/guide-data-modeling/
Important data modeling challenges
Normalization/DenormalizationNormalization is the process of transforming a database to reduce redundancy and increase data integrity and consistency. You need to apply partitions to a database to make each table simpler with a unique key and clearly defined dependencies to avoid any insert, update or delete errors. This will help to save storage by reducing redundancy and allow data flexibility, scalability, accuracy to make changes without affecting other tables.
Zoom image will be displayed

Source: https://phoenixnap.com/kb/database-normalization
But this may cause poor performance in retrieving queries through complex joins especially with distributed or large databases. Hence, we could use denormalization to provide quicker retrievals. Although, this would increase the risk of inconsistencies, we need to strike a balance between the two.
Slowly changing dimensionA slowly changing dimension is a dimension that stores and manages both current and previous version over a history of time period in a data warehouse. There are different types of SCDs:
Zoom image will be displayed
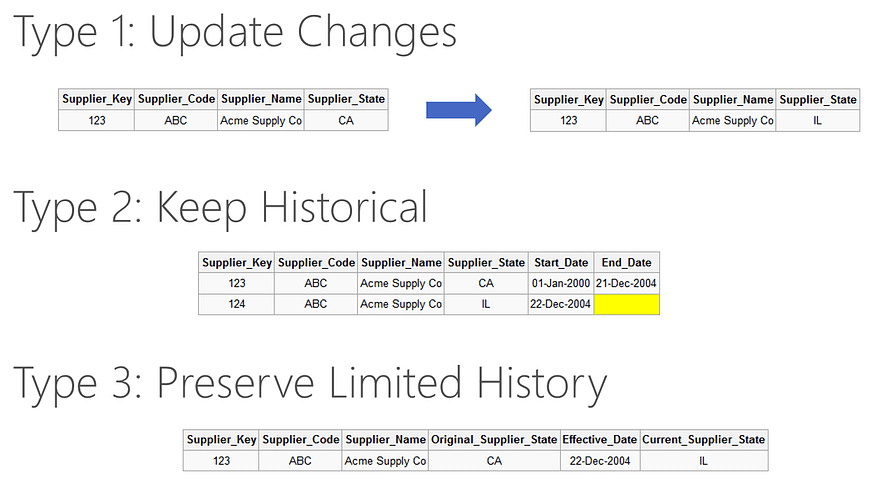
Source: https://radacad.com/temporal-tables-a-new-method-for-slowly-changing-dimension
Sometimes you need to store historical data to provide comprehensive data analysis and that is when you need to use SCDs.
Change data capture Change data capture refers to the process of tracking changes in a database and then capturing them in destination systems. It keeps all systems in sync and provides reliable data replication with zero downtime data migrations. These are the different types of CDCs:
Zoom image will be displayed
Source: https://www.linkedin.com/pulse/change-data-capture-nouhaila-el-ouadi-mqumf/
In ETL, you can use CDC to get the changes from the log, time or trigger and load and refresh only the changed data. And since it supports moving data in real time, it also supports real time analytics and data science.